國防醫學院 林欽副教授 專題演講
1. 部署的真實瓶頸:完美的 AI 也可能卡關兩年
我們的團隊已在 AI 心電圖領域深耕一段時間,不僅發表了多篇論文證明模型的準確度與國際水準相當,更成功取得了 TFDA 核可並完成技術轉移。然而,下一個最重要的目標——將這些演算法部署到各醫院,包括偏鄉與離島——卻遇到了巨大的障礙。
第一個嚴峻的教訓是:一個優秀且獲政府認可的 AI 系統,如果無法在醫院內運行,那它幾乎毫無價值。
實際導入的成本非常高,原因就在於每家醫院的資料格式與存放系統皆不同。舉例來說,工程師光是在一家醫院駐點安裝系統,快則兩個月、慢則半年。更糟的是,有時候會遇到「無人能解的卡點」,導致一個大家都看好的專案,最終卡在那裡長達兩年。這個「最後一哩」問題是阻礙救命技術抵達病患的關鍵障礙。
我深深地體認到,如果沒有國家力量介入,把導入的門檻壓低,光是導入成本就足以讓許多單位望而卻步。因此,衛福部決定推動標準化,對我們而言是極大的鼓舞。有了共同的標準,推廣速度才能真正加快。

2. 隱形的殺手:被忽略的「單位不一致」問題
即使工程師克服了艱鉅的安裝任務,數據本身中仍藏著一個更隱蔽、肉眼難以察覺的問題。
我們團隊在多家醫院推廣心電圖 AI 系統時,實際遇過這樣的狀況:程式能跑、系統也上線正常,但放了兩個月後,準確度竟然驟降。經過追蹤,我們發現問題並非出在演算法缺陷,而是因為一個微小且常被忽略的元資料欄位:心電圖振幅的單位不一致。
心電圖資料可能是 10 秒、5000 個取樣點,如果把它丟進 Excel 畫折線,圖形外觀看起來都一樣。然而,單位可能是毫伏特(mV)或者別的單位,Y 軸刻度不同。對需要絕對精確度的 AI 來說,這種細微的差異卻是災難性的。更令人震驚的是,在我們的調查中發現,我們還沒遇過哪一家醫院的工程師能很肯定地說出自家 ECG 原始訊號的單位到底是什麼。因為通常醫院只是把圖丟給 HIS 供醫師視覺判讀,很少人會追問原始訊號的定義。
這揭示了設計給人類視覺解讀的數據,與機器學習所需的嚴謹、標準化精確度之間存在巨大的落差。如果沒有標準化,AI 就可能一直吃到錯單位的資料,輸出結果當然就會出包。
3. 資料鴻溝:新興醫材與「現成可用資料」的落差
當我聆聽其他同業,例如裴教授分享時,我意識到醫療 AI 發展存在一個雙層系統。
第一個情境,是許多研究者喜歡利用結構良好、標準化且易於取得的「沙盒」資料,這讓開發過程相對簡單。裴教授所談的部分,其沙盒資料真的很完整且好用。
第二個情境,也是我的團隊所面臨的,則是針對數百款不斷更新、獲 TFDA 核可的尖端醫療設備打造 AI。對於這些項目,幾乎都沒有「現成可用的資料」。我們被迫從頭開始,親自處理資料的收集、整理、標準化與上傳。TFDA 清單上的那一百多個新近核可項目,幾乎都沒有現成資料可用,開發過程因此辛苦許多。
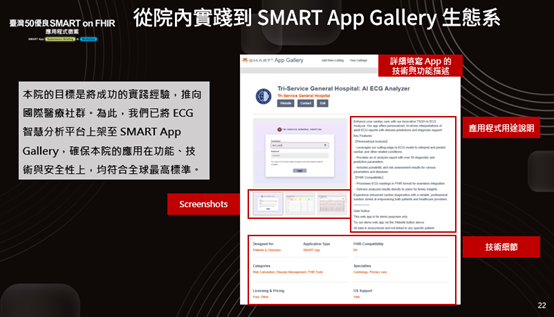
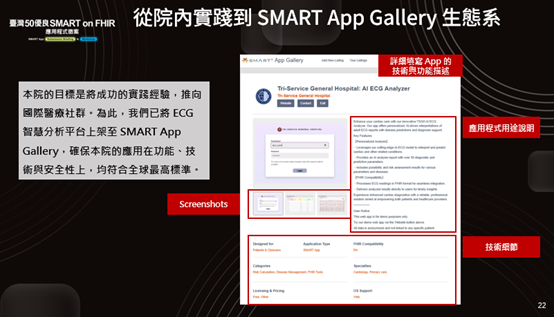
我們很高興我們的應用程式目前已上架到 SMART App Gallery。但由於心電圖本身不是沙盒預設就有的資源,病患清單是我們自行上傳的,暫時不能像其他已內建的資源那樣即取即用。我非常期待未來台灣的沙盒能夠補足這一塊,提供對應的範例資料,這樣大家開發起來就會快很多。
4. 擁抱 FHIR:建立 AI 可用的數據標準
面對這些挑戰,我的感想是:「標準一定要訂。」
我們認為 SMART on FHIR 的機制非常好,它可以用同一套方式去讀取 FHIR 資料,讓系統達到互通。這類計畫(如 FHIR)不僅僅是技術縮寫,它們是建立臨床信任所需的基礎建設。
我們開發的領域(ECG)原本是 FHIR 原生資源比較不充足的領域,但我們仍致力於將不同廠牌的原始訊號(例如 Philips 的解壓亂碼或 GE 的直接數字)轉換成 FHIR。如果沒有 FHIR 的一致化,連同一間醫院內不同系統、不同廠牌都可能需要開兩套平台來看,非常不方便。如果我們能把轉換程式寫好,統一轉成 FHIR,後續整合就會簡單許多。
但目前「心電圖 on FHIR」的標準還需要再補強。特別是,我們需要定義「AI 可用的 ECG on FHIR 格式」,因為目前 FHIR 的 IG 還沒有把心電圖定義完整。標準化不僅僅是 JSON 資料結構,更有價值的是「定義與編碼」,例如量測身高要有對應的標準名稱與碼,心電圖也應有相應的編碼。尤其要確保單位(metadata)被完整且正確地記錄。
理想狀態是:未來各院導入 AI 系統,不用再耗時動輒數月,甚至卡關導不進去。我們需要透過國家的力量,把導入門檻壓低。
最後,我想再次強調:要把事情真正做好,我們需要持續投入,同時也需要各院一起努力。有了共同的標準與誘因,各院才有更大的動力往前走。缺乏這些基礎,即使是最聰明的人工智慧,也將會被困在實驗室裡。