主講人:林嶔 副教授/ 國防醫學院
次世代數位醫療辦公室 技術組廖柏鈞工程師節錄摘要
一、以國家級聯邦學習框架建構醫療 AI 標準化生態系
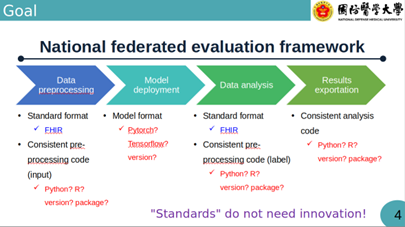
在這次聯邦學習高算力中心啟動大會的演講中,林嶔副教授提到加入國家級聯邦學習平台,除了能參與衛福部指定的 16 家醫院合作外,更重要的是建立一個能夠持續擴展的醫療 AI 生態系 。未來三軍總醫院也將準備進行多項專案,並期待更多醫院加入,共同整理資料以進行全國性的 AI 模型訓練與驗證 。之所以會有聯邦學習的構想是因為外部驗證對於 AI 臨床應用至關重要 。美國 FDA 於 2025 年 1 月發布的草案指引中提到,臨床驗證數據應至少包含來自三個地理區域多元化的臨床場域,才具備代表性 。雖然臺灣沒有如此嚴格的指引,但在臨床上林嶔副教授也提到,當 AI 模型從開發端部署到其他醫院時,常因「資料領域偏移」(如:不同顯像設備)、「人群偏移」(如:年齡、共病症分布)或「工作流偏移」(如:醫囑習慣、缺失資料)而導致準確度大幅下降 。而目前因受限於病人隱私、法律責任及機構治理,醫院通常不允許資料離開院內 。這使得傳統的外部驗證不僅溝通成本高昂,執行起來也極其困難 。聯邦學習平台的核心目標便是建立國家級聯邦學習的框架,解決開發者最頭痛的環境不一致問題,達成以下成果:
-
資料標準化 (FHIR):推動以 FHIR (Fast Healthcare Interoperability Resources) 作為資料標準格式,確保輸入與標註的數據具備一致性 。
-
環境與版本統一:不再糾結於 Python 或 R 的版本差異或開發框架(如 Pytorch、Tensorflow)的相容性,正如李處長所強調:「標準不需要創新,標準就是標準」。
-
降低溝通成本:透過統一的 Package 和版本,模型開發者與醫院工程師間的溝通成本將大幅下降 。
二、NVFLARE 的核心價值:安全性、靈活性與國家級標準化
林副教授於演講中也讚許衛福部聯邦學習平台基於 NVFLARE 架構開發的正確選擇 ,這是因為使用NVIDIA的NVFLARE可以達到以下效果:
-
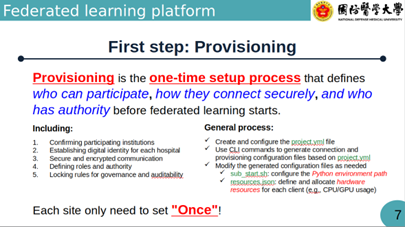
一次性配置 (Provisioning):醫院端僅需進行一次設定,即可建立安全加密的連線與數位身分識別 ,下次醫院被分配到不同專案時仍可使用同一個Provision進行訓練。
-
資源可控:醫院可透過 resources.json 自行定義與分配硬體資源(如指定使用的 CPU/GPU 數量),不影響日常運作 。

-
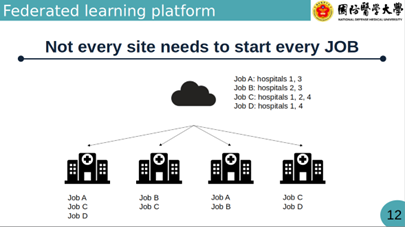
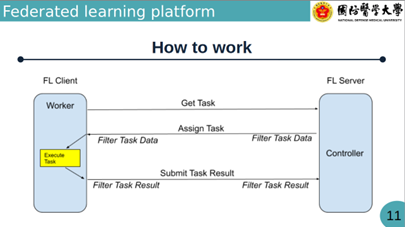
主動參與機制:醫院扮演「Worker」角色,由醫院主動領取任務(Get Task) 。且並非所有醫院都必須參加每一個專案,各院可自由選擇感興趣的 Jobs (專案) 參與 。
-
資料不出院:分享的資訊僅限於差分隱私處理後的模型參數(Weights)與準確度(Accuracy),病人的原始資料絕對保留在院內 。
-
零信任架構:系統設計假設參與者互不信任,所有通訊皆經端到端加密與身分驗證 。

-
完整追蹤紀錄:平台會詳實記錄「誰在何時對哪個模型做了什麼」。這對於 TFDA 審核至關重要,能證明驗證過程未經數據修改,確保科學嚴謹性 。

三、三軍總醫院未來接軌聯邦學習平台啟動多模態 AI 驗證專案
最後,林嶔副教授也分享了目前三總預計使用衛福部高算力中心的兩個聯邦學習專案:
-
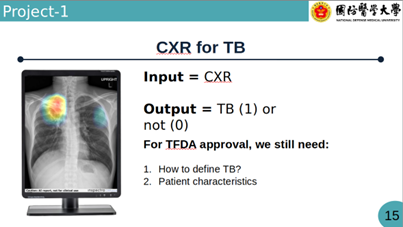
CXR 影像預測:透過胸部 X 光影像判斷患者是否有肺結核 。在申請TFDA時有意參與聯邦學習的醫院需準備 ImagingStudy、診斷報告、病人特徵及 ICD 疾病史 。
-
乳房攝影預測:透過乳房攝影預測患者是否罹患乳癌 。若有意參與此聯邦學習專案的醫院在申請TFDA時同樣需準備TW-Core (FHIR) 格式整合 DICOM 影像的相關病歷 。
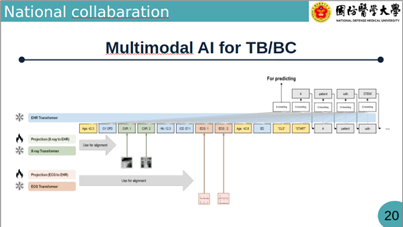
期盼透過整合多模態資料(影像 + 疾病史),並利用平台留存的 Log 作為 TFDA 查核的標準依據,臺灣將能建立更公正、精準且具備國際競爭力的 AI 醫療環境 。