主講人:Dr. Cherdchai Nopmaneejumruslers
Vice President for Information Technology and Digital Transformation, Mahidol University
一、跨國合作的起點:臺灣與泰國面臨的共同醫療 AI 挑戰
在醫療領域,無論是臺灣或泰國,醫療院所都面臨相同的困境:個別醫院的數據樣本其實非常有限,而大型醫學中心的病例雖然複雜,但並不能代表整體人口的疾病型態。正如泰國瑪希敦大學於演講中所點出的,醫學生在醫學中心看到的病人,其實只是整體社會的一小塊,且往往是病況較重、特例比例較高的族群。這些特性導致 AI 模型若僅依賴單一機構的資料進行訓練時,無法真實反映不同醫療現場的差異,也難以被推廣到更廣泛的人群。
臺灣也面臨同樣問題。儘管臺灣擁有高密度醫療體系與完整健保資料,但大量影像、訊號與非結構化資料仍分散於各院所,加上疾病嚴重程度、就醫流程差異,使得 AI 模型跨院驗證常出現準確度下降的情況。正因如此,衛福部資訊處李建璋處長在多次國際交流中皆強調:要真正讓 AI 在臨床落地,必須收集能代表不同族群與不同醫療情境的資料,而不是只依賴單中心資料。這項理念也是臺灣與泰國攜手合作的核心出發點。
在這樣的背景下,臺灣與泰國看見彼此的互補性。泰國擁有大量人口族群的疾病資料及熱帶疾病特徵,但在不同地區的醫療資源卻存在巨大落差;臺灣則擁有成熟的醫療資訊系統與主權雲基礎。透過跨國協作,雙方能以實際臨床差異互補資料不足,讓醫療 AI 能反映真實人群,並提高模型在亞洲人口的適用性。

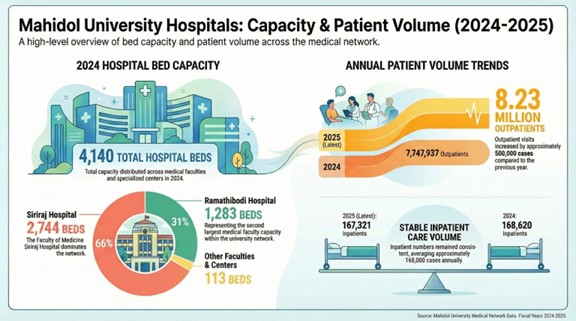
二、醫療 AI「泛化性危機」:為何 95% 模型無法落地?
根據泰國瑪希敦大學副校長 Cherdchai 教授的簡報,全球醫療 AI 正面臨所謂的「Generalizability Crisis(泛化性危機)」,這也是為何多數醫療 AI 模型無法從研究室走進臨床的重要原因。簡報中指出,當 AI 模型移到不同醫院或不同人口時,往往出現準確度大幅下降的現象,這就是所謂的「Accuracy Paradox(準確度悖論)」。模型在單中心的乾淨資料上表現極佳,但一旦導入真實世界流程,就會因環境差異而失效。

造成這些落差的深層原因,在於「單中心陷阱(Single-Center Trap)」,多數 AI 是在乾淨、標準化、單一族群的資料上訓練,因此過度適應(overfitting)於特定醫療環境,包含儀器設定、影像風格、診斷流程、疾病嚴重度分布等因素。簡報更清楚整理出 AI 失效的「六大隱形偏差」,包含疾病嚴重度分布偏差(Spectrum Bias)、競爭性疾病(Competing Diseases)、標記不完美(Imperfect Labels)、資料外洩(Data Leakage)、標記者偏差(Review Bias)、驗證偏差(Workup Bias)。這些問題若未被處理,AI 將不可能在跨院應用、跨國使用。
這些現象不僅出現在泰國,臺灣也長期面臨不同地區醫院的疾病嚴重度不同、設備差異與人口結構不一,使得醫學中心訓練的 AI 模型在地區醫院常常準確度大幅下降。因此,臺泰雙方都必須尋找一個能「不集中資料」且能同時「修補多中心偏差」的方法,才能真正讓 AI 在臨床被信任,這也引出後續聯邦學習的關鍵角色。
三、聯邦學習的跨國解方:臺泰共同架構的技術藍圖
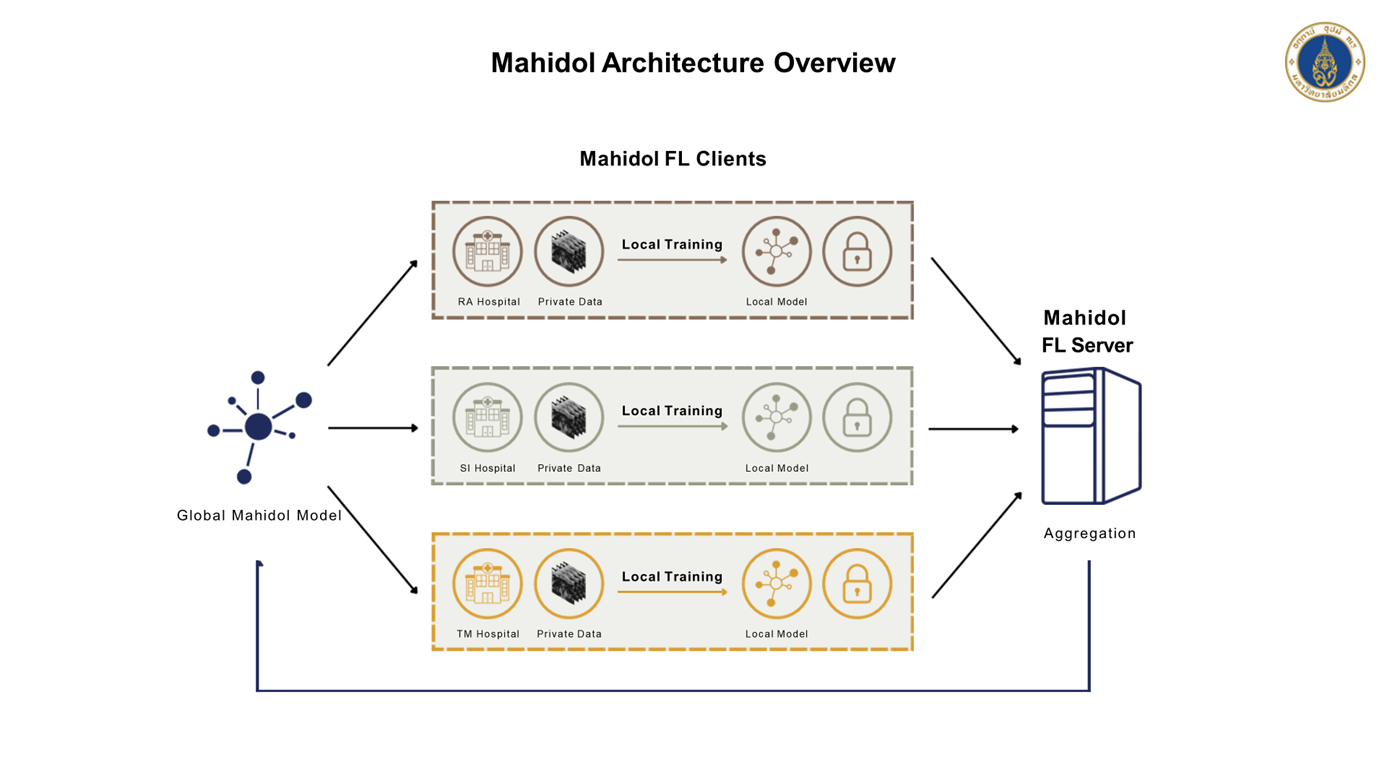
在資料無法集中、法律限制不同的前提下,臺灣與泰國皆認為聯邦學習(Federated Learning, FL)是跨國合作最可行且永續的解方。聯邦學習允許「資料留在各自的醫院」,僅將模型參數回傳至中央伺服器進行聚合,不需要移動任何病患個資,完全符合兩國隱私與法規要求。
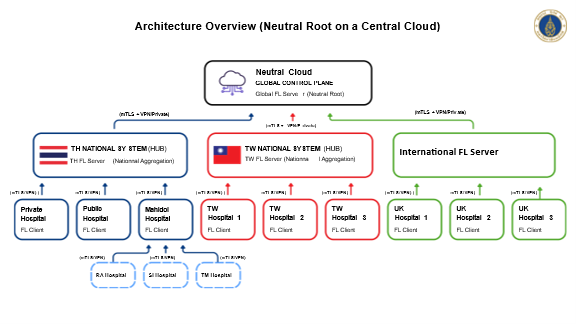
目前臺泰合作採用「雙國家級聚合(National Hub)+院所節點(FL Clients)」的架構設計:臺灣端使用主權雲與國家級 HPC 建置中央聚合伺服器;泰國端則由瑪希敦醫院及多家公私立醫院作為聯邦節點,兩國再共同連接至 Neutral Root(國際 FL 中控),以便後續擴大更多國家與機構的參與。這代表臺泰合作並非單一醫院之間的API串接,而是「國家核心 × 國家核心」的深度對接。
在實作上,雙方必須共同定義資料治理、隱私保護、mTLS/VPN 安全傳輸機制、聯邦聚合頻率、模型版本控制與回滾流程等細節,逐步將兩國資料特性融合,使模型具備跨族群的強韌性與可靠性。李建璋處長指出,我們的目標不是建立另一個集中式資料庫,而是與國際夥伴共同打造一套可以被信任的醫療 AI 訓練生態系,讓各國能在保有資料主權的前提下合作,並為未來多國聯邦學習奠定標準。
四、GLIMMERS 腦瘤、攝影 AI 與 MAP:跨國案例示範與早期成果
在臺泰合作的初始階段,雙方選擇了數個具代表性且高度臨床價值的專案作為示範。其中之一為中樞神經腫瘤(CNS Tumor)分類計畫 GLIMMERS。泰國端提供約二百位病患的基因序列資料,涵蓋兒童與成人族群,並結合 Nanopore 定序技術與機器學習,用以精準分類腦瘤亞型。未來若能透過聯邦學習與臺灣資料進行跨國驗證,將有機會建立亞洲首批真正具跨族群代表性的腦瘤 AI 模型。
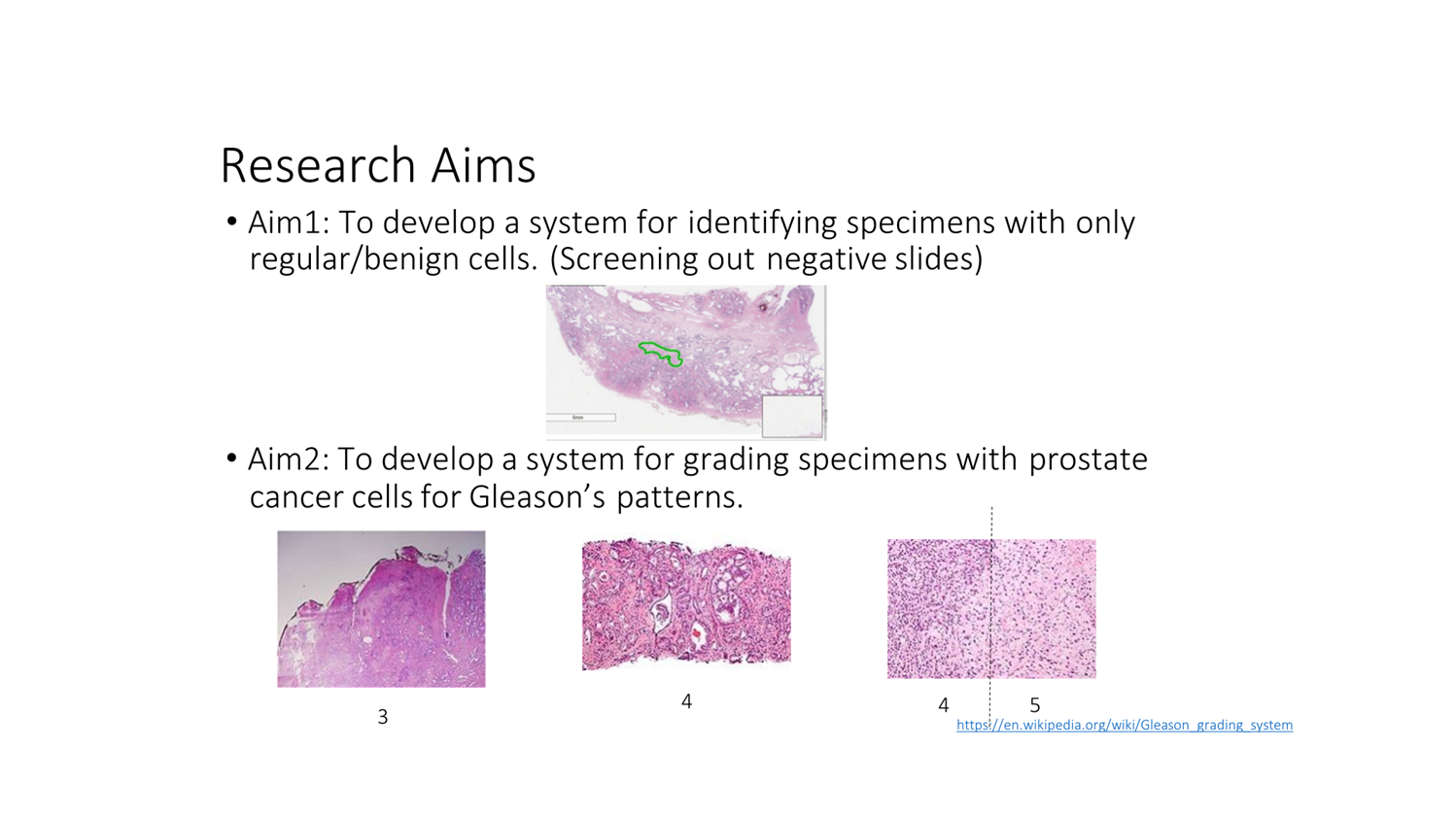
其次,在影像領域,雙方也針對乳房攝影、前列腺病理切片與慢性疾病(NCD)等主題規劃示範專案。泰國在疾病分布、患者年齡層與儀器品牌上與臺灣截然不同,正好可成為檢驗模型泛化能力的最佳場域。透過聯邦學習機制,臺泰雙方可以在不交換原始影像的情況下,共同訓練與更新模型參數,讓模型在兩國臨床環境中都能維持穩定表現。
此外,合作架構中也納入 MAP 與其他醫療 AI 平台的整合構想。泰方在演講中提到,希望未來臨床醫師只需將影像、心電圖與生理訊號上傳至平台,就能產生臨床決策輔助建議,並透過安全架構回饋到各院所的既有系統之中。這些跨國示範不僅驗證技術可行性,更是將研究成果推向實際醫療服務的重要一步。
五、2026–2030 臺泰合作願景:打造亞洲醫療 AI 生態系
根據雙方共同擬定的規劃,臺泰聯邦學習合作已畫出清晰的 2026–2030 路線圖。2026 年,雙方將成立雙邊委員會,確認示範模型清單,擬定技術測試方案與治理原則,為跨國驗證建立制度基礎。接著在 2027 年,將於泰國啟動第一個醫療 AI 驗證場域,由瑪希敦大學與其醫院網路合作,在真實臨床情境中測試臺灣與泰國共同開發或調校的模型。
到了 2028 至 2030 年,合作將進一步擴大為區域級與全球級的 AI 驗證樞紐。透過雙國主權雲與聯邦學習架構,吸引來自歐洲、美國與其他亞洲國家的醫療 AI 團隊,將臺泰視為亞洲人口資料與臨床驗證的首選據點。臺灣在此過程中扮演主權 AI 技術與治理框架的提供者角色,泰國則提供多元的族群特徵應用在這套藍圖下,臺泰合作不僅是兩國之間的技術交流,更朝向共同打造「亞洲醫療 AI 生態系」的願景邁進。未來凡是需要亞洲人口資料驗證的國家與企業,都能透過這套聯邦機制參與合作,讓每一次模型訓練與驗證在不同疾病場景的臨床驗證場域,都能同時強化彼此的醫療能力與病人照護品質。
