SNOMED CT TAIWAN 2025 國際研討會暨工作坊
建構次世代智慧醫療基礎:從語彙標準化到電子病歷升級
─ 衛福部呂建德次長、李建璋處長聯合專題報導
全球智慧醫療浪潮與臺灣的角色
在全球智慧醫療快速發展的浪潮中,醫療資料的結構化與一致性已成為推動人工智慧應用、促進資料互通、實現精準醫療的關鍵基礎工程。衛福部政務次長呂建德於致詞時指出,無論是 AI 模型訓練、跨院資料整合、法規應用或公共健康監測,都仰賴語彙標準化與資料互通。他強調:「臺灣已積極導入 SNOMED CT、LOINC、RxNorm等國際標準,並公開在臺灣醫療資訊標準大平台,提供各界下載使用。」此次研討會不僅是技術交流,更是臺灣在醫療資訊標準化進程中邁向國際的重要一步。呂次長代表衛福部,感謝國內產官學研各界的努力,也特別歡迎來自 SNOMED International 的專家蒞臨台灣分享國際經驗,強化臺灣與全球接軌的競爭力。
呂次長引言:以病人為核心,打造智慧健康生態系。呂次長在致詞中特別強調,臺灣具備兩大優勢:首先,全民健保覆蓋率高達 99.99%,資料完整度舉世罕見。其次,半導體與數位科技領先全球,為醫療 AI 發展奠定堅實基礎。他指出,結合這兩大優勢,臺灣有條件推動「以病人為核心(Patient-Centered)」的智慧健康生態系,並呼應賴清德總統提出的「健康臺灣」願景。呂次長進一步表示:「此次會議不僅是一場工作坊,而是臺灣建立制度性語彙治理機制的重要起點。我們將持續規劃 SNOMED CT 導入藍圖,建構專業培訓與治理制度,協助醫療機構系統性導入標準,真正落實結構化資料的價值。」
資料是 21 世紀的石油
隨後,衛福部資訊處處長李建璋以錄影方式發表演講。他首先因颱風值勤無法親臨致歉,並以「資料是 21 世紀的石油」開場,強調資料品質決定 AI 的成效:「Garbage in, Garbage out。沒有好的資料,就沒有好的 AI。」電子病歷是智慧醫療最龐大的資料來源,但大部分內容以文字呈現,不利於統計與分析。傳統上,需將文字結構化成欄位,例如放入 Excel。然而,醫療用語存在同義詞差異,如「Irritable Bowel Syndrome(腸躁症)」與「Irritable Colon Syndrome」會被電腦視為不同類別,必須透過標準化同義詞才能有效分析。

圖一、臨床用語不一致,概念與同義詞的挑戰
臨床資料檢索的困境
李處長舉例:新乳癌藥物臨床試驗往往鎖定「Invasive Ductal Carcinoma, Grade 3」且具特定受體狀態的病人。若僅依健保 ICD-10 編碼,無法涵蓋病理分級與受體資訊,研究者仍需逐一翻閱病理報告,耗時耗力。「光是找合適病人,就已經極度消耗人力,更何況後續複雜的品質統計與研究。」李處長感嘆。這正突顯了需要一套更細緻、全面的醫學名詞編碼系統。
SNOMED CT:最完整的臨床語彙標準
SNOMED CT 便是解決方案。它擁有超過 100 萬個編碼,相較 ICD-10 的 9.8 萬筆更加精細。這種「顆粒度細」的特性,能編碼病理變化、嚴重度、受體狀態,並內建同義詞與關聯群(Concept Relationships)。這意味著研究者可一次抓取整組相關疾病或症狀,例如「所有自體免疫疾病」或「藥物副作用症狀」,大幅提升檢索與分析效率。李處長形容:「SNOMED CT 就像煉油廠,把資料原油轉化為可再利用的知識燃料,讓電子病歷成為『知識生產的機器』。」然而,僅有名詞標準化仍不足,還需將病人完整就醫歷程整合。李處長介紹 Common Data Model(CDM)(如 OHDSI/OMOP),可將不同階段資料串接成統一結構。「SNOMED CT 是珠子,CDM 是把珠子串成項鍊。」李處長比喻。若全台醫院採用相同標準,便能形成全國性 Real-World Data 平台,補足健保資料庫缺乏病理與影像資料的限制,並與國際合作無縫接軌。
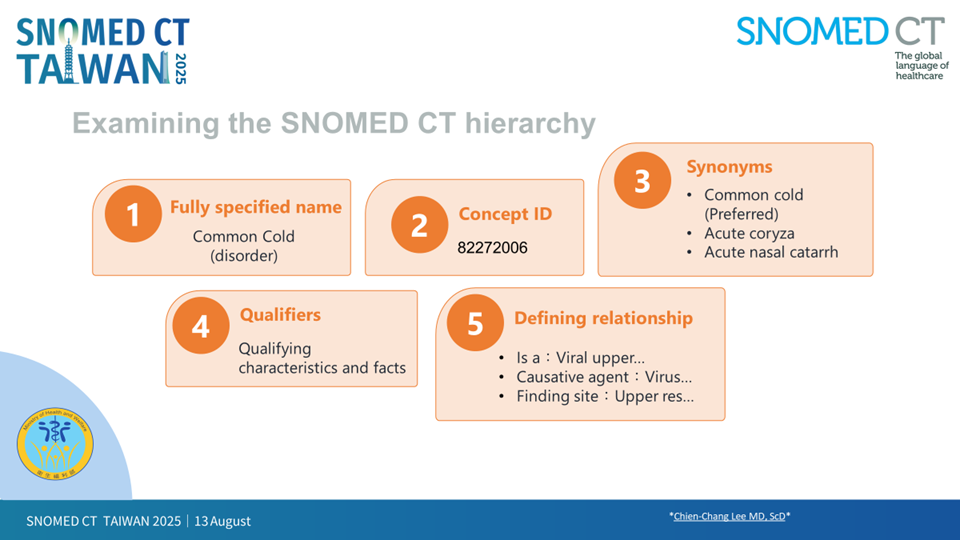
圖二、SNOMED CT 的階層結構,以「普通感冒」為例
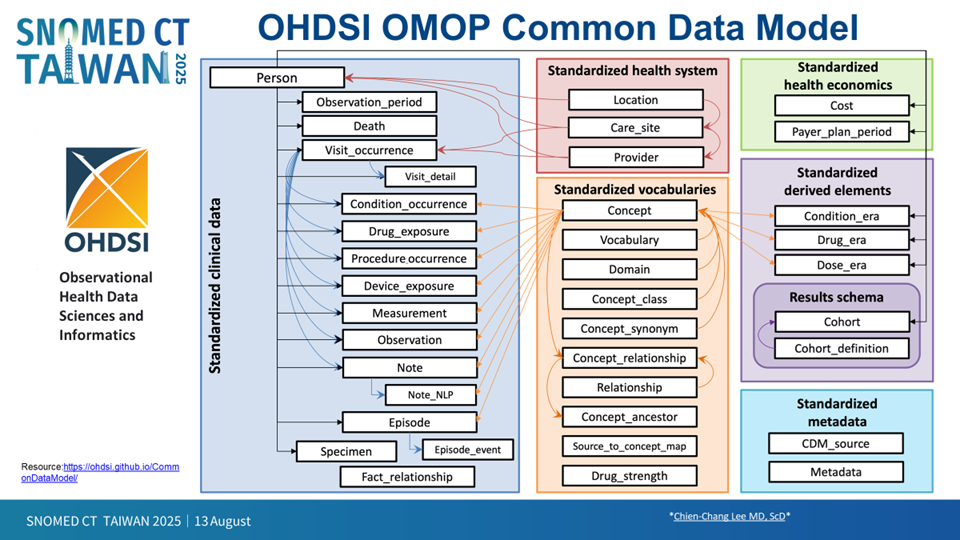
圖三、OHDSI OMOP 通用資料模型架構

圖四、SNOMED CT 與 OHDSI OMOP CDM 結合,讓電子病歷能夠進行分析
AI 與大語言模型:加速醫學編碼
SNOMED CT 優勢明顯,但龐大的編碼量也帶來挑戰。疾病分類管理師平均需 30 分鐘編碼一份出院病歷,若使用 SNOMED CT,時間恐增至十倍。因此,解方是結合大語言模型(LLM)。然而,臺灣病歷常見中英夾雜、縮寫混亂、拼字錯誤,直接交由模型判讀會錯誤百出。因此必須先經過前處理(Pre-processing),將縮寫展開、藥名標準化,再交由 LLM 判讀。目前,衛福部與工研院已開發出原型系統,能自動標註SNOMED CT、LOINC、RxNorm,並提供信心值與來源標示,供疾病分類管理師複核。開發工具的過程,掌握人工智慧基本倫理,亦即自主、當則、透明等原則,此舉既減輕人力負擔,也提升準確率。
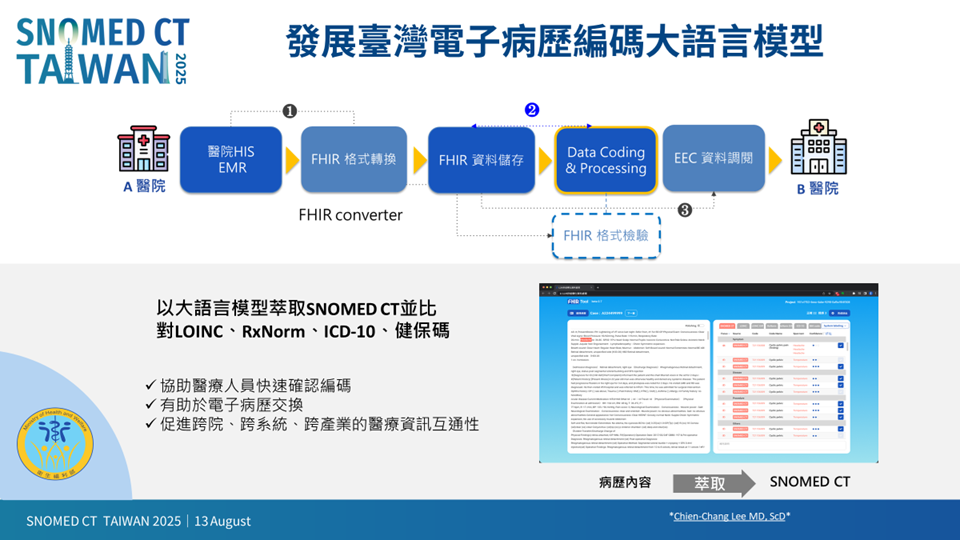
圖五、發展臺灣電子病歷編碼大語言模型
FHIR:跨院資料交換的國際標準
在智慧醫療的發展進程中,如何統一台灣電子病歷的思維與標準,成為當前最重要的課題之一。然而,即使院內資料結構化,若缺乏交換機制,跨院仍難互通。李處長指出FHIR(Fast Healthcare Interoperability Resources)是解決方案,台灣亟需建立「資料中台」,作為醫學中心與各大醫院電子病歷交換的核心平台。資料中台的概念,是先將各醫院現有成熟的電子病歷集中到一個伺服器,再透過 FHIR這一國際交換標準,完成跨院與跨系統的資料互通。這種作法並非台灣獨有,美國與歐洲早已大力推動。例如美國前總統川普便以「Health Technology Great Again」為口號,推動全美採用 FHIR 建立醫療生態系。
FHIR的價值不僅在於醫院與醫院之間的轉診,更在於創造一個全球性的醫療應用生態系。FHIR不同於 OMOP Common Data Model 主要用於生成分析用的資料表格(Spreadsheet),FHIR不僅具備結構化的資料模型,更定義了網際網路交換的標準,透過 Restful API、模組化設計與 JSON 格式,使醫療資料能靈活且安全地進行交換。將病歷拆分為135個模組化資源,方便不同HIS系統交換。只要資料格式統一,開發商就能以單一程式支援多家醫院,推動自主健康管理APP、人工智慧應用與臨床決策工具的發展,並進一步與國際標準接軌。FHIR中台不僅資料交換、支援轉診,更能建立全球互通的智慧醫療生態系:健康管理App、AI輔助診斷應用、醫院內部應用程式;在統一資料格式下,開發者可一次開發、全球適用,加速醫療科技創新。
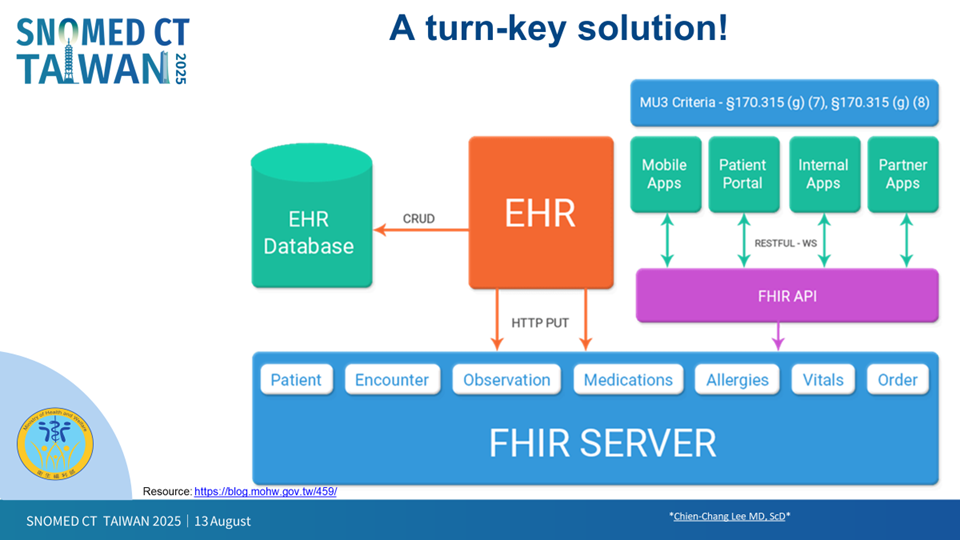
圖六、FHIR 架構如何成為電子病歷(EHR)互通的完整解決方案
臺灣的三層資料標準化策略
- Taiwan Core(TWCDI):台灣核心資料集20類別、109項核心變數,作為結構化基礎。
- Terminology標準化:SNOMED CT(疾病)、RxNorm(藥品)、LOINC(檢驗),確保內容互通。
- FHIR資料交換:建立跨院、跨國交換能力,對接IPS(International Patient Summary)等國際標準。
這三層相輔相成,使臺灣能逐步完成電子病歷的「標準化、互通化、應用化」。

圖七、台灣電子病歷標準化架構,從結構互通到語意互通
一條龍工具與示範醫院
「一條龍工具」流程:
1. 對應 Taiwan Core 欄位 →
2. FHIR Converter 轉換為 FHIR JSON →
3. 存入 FHIR Server →
4. LLM 自動編碼 SNOMED CT / LOINC / RxNorm →
5. 驗證與視覺化呈現 →
6. 傳送至 EEC(電子病歷交換中心)交換。
一條龍工具示範,目前已在林口長庚與中山醫院測試,未來將擴展授權全台醫院與系統廠商使用。
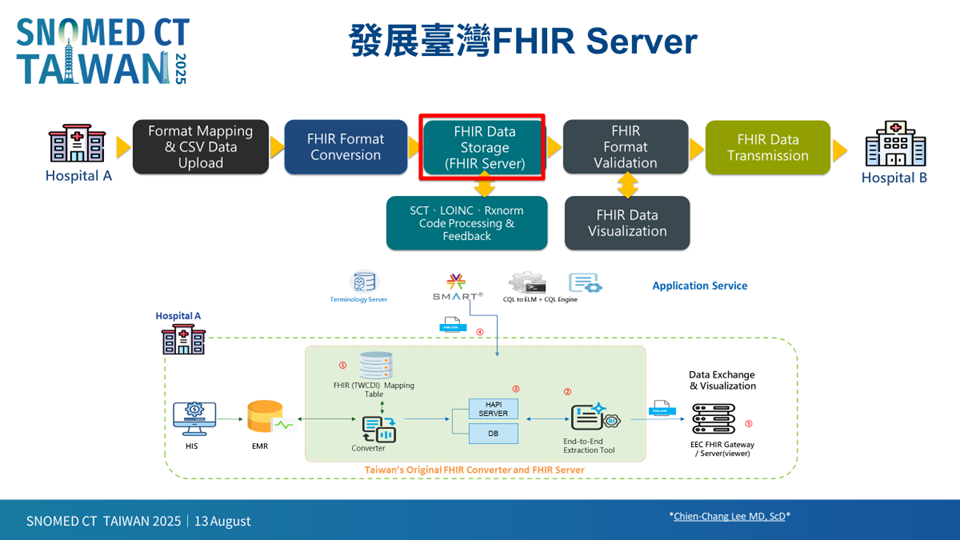
圖八、從醫院到跨院共享,FHIR Server 的一條龍流程

圖九、跨院合作試點,推動電子病歷互通與驗證模式
結語:邁向以病人為核心的智慧醫療新時代
綜合呂次長的政策願景與李處長的技術藍圖,臺灣智慧醫療的發展已清楚描繪出完整路徑:從標準化奠定資料結構基礎、到工具化提供臨床一線可立即上手的支持,再到生態系建立規則庫與應用市集,串聯臨床、健保與AI研究,逐步打造一個可持續進化的醫療體系。這不僅是一個技術升級的過程,更是一場以病人為核心的制度革新。當電子病歷從單純的紀錄容器,進化為能持續產生洞見與價值的「知識生產機器」,臺灣便擁有了推動全民健康、驅動醫療創新的新引擎。
站在這個關鍵轉折點,臺灣正以透明、準確、可共享的資料治理,為國內醫療品質帶來飛躍,也在國際舞台展現前瞻與領先。我們正邁向一個智慧醫療全面落實的新時代,在這裡,醫療不只是治療,更是以病人為核心、以資料為動能的健康願景。
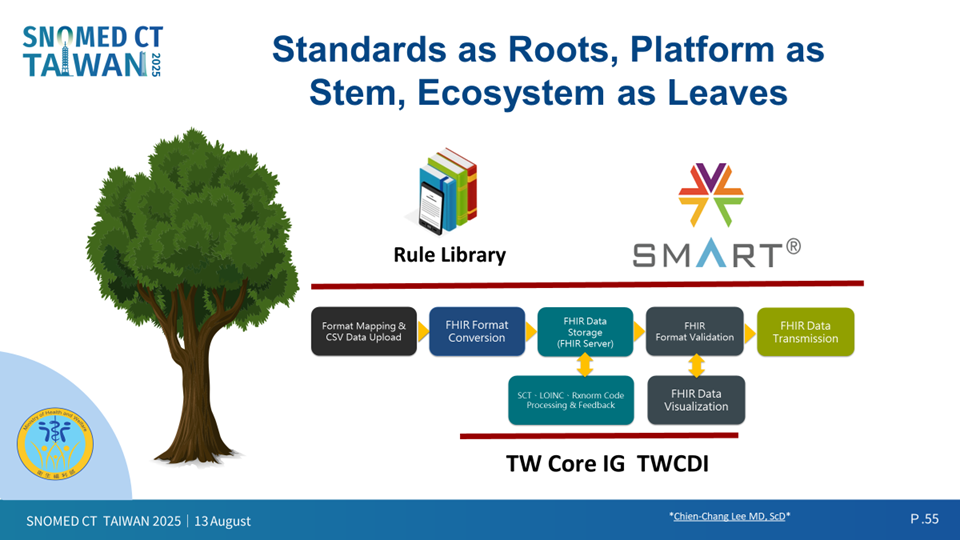
圖十、打造智慧醫療生態樹 | TW Core × FHIR × SMART on FHIR